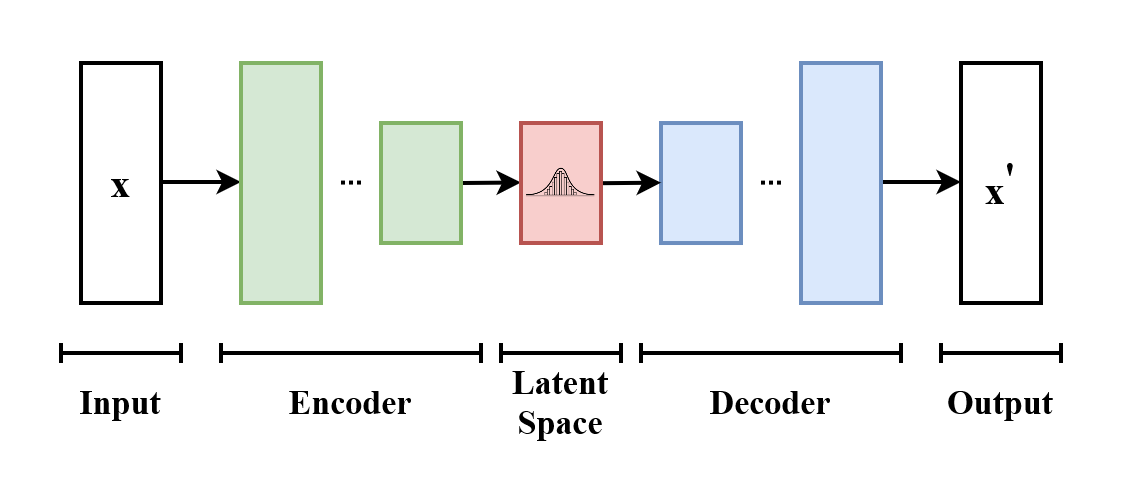
基于 deep learning 的降维算法。
模型由 encoder、decoder 构成,其中 encoder 用于将输入的高维向量编码到低维的 embedding,而 decoder 用于将 embedding 还原到原本的向量空间。
直观上讲,AutoEncoder 之所以能够实现,是因为输入样本的复杂度小于其向量空间维度。一个极端的例子是,对于 的图片,样本空间总共只有两张不同的图片,那么只需要 1 bit 就足以编码该样本空间。
有了这个 embedding,就可以用来做一系列 downstream 的任务。
encoder、decoder的详细结构?
- Feature Disentanglement:尝试将 embedding 拆分成不同部分,每个部分代表了输入的某一方面特征。例如,对于语音输入,尝试将 embedding 拆分为音色、内容两部分。可以应用到风格迁移中。
- Discrete Representation:尝试用离散值(例如 01 编码、one-hot 编码)来表示 embedding。
- ...... (text as representation、tree as representation)
该部分内容(尤其是数学推导)主要来自:张振虎的博客 ,其中的内容与Understanding Diffusion Models: A Unified Perspective 的推导类似。
与 AE 的总体架构类似,二者的关键区别在于,AE 编码器输出的 embedding 只是一个张量,而 VAE 则是一个随机变量,该随机变量的均值和方差由编码器给出;同样的,确定 embedding,VAE 解码器输出的也是一个随机变量,其均值由解码器给出,方差为 。记输入为 ,输出同样也是 ,embedding 为 。
Note
AE 的目标是使得输入输出相同,所以这里使用了相同的符号 来表示,但是在推导时需要区分。具体而言,考虑如下情形:
- 可观测变量 :极大似然指的是使得输出变量符合样本,所以这里指的是输出样本,然而对于 AE 而言,样本输入输出相同;
- :指的是输出;
- :指的是输入。
通过极大似然求解? 如果通过极大似然法求解,需要极大化观测样本的发生概率。在这里,只有输入 是可观测的,VAE 的中间 embedding 并不能观测到(其值为何完全由 VAE 决定,不由样本给出)。因此,对数似然函数为:
然而,这个式子无法数值求解。
Note
为什么要对隐变量 展开?
只看 没法进一步展开,而对隐变量 展开实际上是结合了 生成的实际过程,从而使得接下来的所有推导成为可能。
expand to see preliminaries
在机器学习领域中,常使用期望的下标来表示随机变量 服从分布的概率密度函数:
既然无法直接求解 ,能否找到一个近似表达呢?答案是可以的。首先需要引入一个 的概率密度函数 ,其中 是未知的参数。然后,可以将进行如下化简:
由此,可以得出对数似然函数的一个下界 ,又因为它是证据 的下界,因此叫做证据下界。
对于中的 项,可以作如下分解:
通过两种不同的分解方式,可以分别对 ELBO 进行变换,得出对应的结论。
第一种变换
expand to see preliminaries
KL 散度的定义:
观察可以发现,当 KL 散度越小,也就是 与后验 的区别越小时,ELBO 越接近目标对数似然函数。当 KL 散度为 0 时,二者相等,此时就可以完全使用 ELBO 来近似目标函数。而 是一个任意的未知分布,所以可以直接令该等式成立。
第二种形式
Note
不参与时, 的分布并不受到参数 的影响(至少在 VAE 中如此),所以上述推导中,直接将 写作了先验 。
从第一种形式的推导中可知,当 时,,即:
为了便于区分,这里将参数 进行细分,对于指导 生成的部分参数,使用 来表示,剩余的参数沿用 。最终得到如下 ELBO / 损失函数表达式:
解释
- 重建项表示了模型重建原始数据 的能力。其中, 表示了给定 ,模型重建出 的概率;又因为隐变量是一个随机变量,所以要对 求期望,其服从分布的概率密度是后验概率 。
- 为了极大化目标函数,需要最小化先验匹配项,即使得 与 尽可能接近,它的作用其实就相当于一个约束或者正则项。
 Figure 1: Architecture comparison between AE and VAE.
Figure 1: Architecture comparison between AE and VAE.在 VAE 中,假设 服从高斯分布,其先验分布为 ;输出 同样也服从高斯分布,并且假设其协方差始终为 。
因为 服从高斯分布,因此其后验分布 也是高斯分布,用 和 来表示其均值和协方差矩阵。编码器做的实际上就是通过输入变量 计算得到隐变量 的后验分布 的均值和方差,而隐变量的值,则由该高斯分布采样得到。后验分布 的计算过程取决于参数 ,这也就是编码器的参数。
与编码器类似,解码器也是从隐变量 计算得到输出变量 的分布参数。但是为了模型的简单,这里假设输出变量 的方差为 ,只计算其均值 。计算过程取决于参数 ,这也就是解码器的参数。
先验匹配项中的两个概率密度函数可以给出表达式:
两项都是高斯分布,而两个高斯分布的 KL 散度可以直接得到:
损失函数的表达式已经给出,但是要作为神经网络训练的损失函数,必须满足:可数值求解,可求导。先验匹配项已经满足,但是计算重建项却存在如下问题:
后验分布 的表达式中含有神经网络,无法解析计算期望。可以采用 MCMC 近似求解:
随机过程不可求导,梯度无法传递。作者使用了重参数化来解决:对于在 中采样的值,可以通过 来得到。转化后的式子将随机化控制在了一个参数无关的 中,从而使得随机采样值可以传递梯度。
解决了以上两个问题后,就可以给出损失函数的最终表达式:
expand to see details of preliminaries
条件概率密度
条件概率密度函数 ,准确来说应当是 ,指的是在 的条件下 的概率密度函数。可以通过如下公式计算得到:
另一种常见的写法 ,则是指在事件 发生的条件下,事件 的发生概率。
对于理解 的一点:对于 来说, 都是变量;只是在条件变量中,将 视作一个参数进行固定。哪怕x不确定,为输入,我们仍然能够写 py|x
联合概率密度
联合概率密度 被解释为 且 时的概率密度。
对于多元联合分布,有:
 Figure 2: Architecture of MHVAE.
Figure 2: Architecture of MHVAE.将 VAE 的过程重复 次,无论正向编码还是反向解码,当前时刻步仅与上一时间步相关,就得到了 MHVAE(Markovian Hierarchical Variational Autoencoder)。 表示了单次编码过程,而 表示了单次解码过程。由于该过程为马尔可夫过程,因此有:
由此,可以得出模型的联合概率分布、隐变量 的后验概率分布分别如下:
与 VAE 的 ELBO 推导过程类似,我们可以得出 MHVAE 的 ELBO: