PA3
PA3
Overview
完成 PA2 之后,我们在 nemu 中模拟出了设备,并且在 abstract-machine 中实现了与设备交互的 API(抽象为对设备寄存器 io_read/write )。但是,am只是一个裸机环境,上述 API 在和硬件进行直接交互,很难在此基础上运行复杂的程序。
于是,PA3 首先引入了操作系统 nanos-lite。而在操作系统中如何获取资源、与设备交互?系统调用。为了支持系统调用,我们首先要实现中断机制,然后,只需要在中断处理程序中根据不同的中断号,实现对应的功能即可。同样,基于系统调用 API,还是很难运行复杂程序,因此,PA3 引入了第二个模块:替换了系统调用函数实现,包含了 SDL、libc 等库的 navy-apps。为了能够在 nanos-lite 上运行,navy-apps 使用了最小的 libc 实现,并且在 libos 中重新实现了 _open() 、_write() 等函数,使得其能够接入 nanos-lite 的系统调用机制。有了 navy-apps 的运行时环境支持,我们就能够像在真机上一样,自由地编写程序了。例如,如果使用了 printf,则 navy-apps 的 libc 会自动帮我转换成对 _open() 、_write() 等函数的一系列调用。但是,PA 的任务并不是让我们基于 SDL 等库进行编程,所以在 PA3 中,navy-apps/apps 中的各种程序充当了测试用例,而我们要做的,正是实现 SDL 等函数库。
Comprehensions
运行 nanos-lite 的 nemu 内存布局
navy-apps 首先将所有应用、资源打包为 ramdisk.img(因为后续还要加载到非 0x80000000 的位置,所以这里打包了应用的 elf 文件),并且将各文件偏移量记录在 file.h 中。随后,nanos-lite 通过链接脚本:
.section .data
.global ramdisk_start, ramdisk_end
ramdisk_start:
.incbin "build/ramdisk.img"
ramdisk_end:
.section .rodata
.globl logo
logo:
.incbin "resources/logo.txt"
.byte 0将 ramdisk 包含到 nanos-lite 的可执行文件中。而在加载时,nemu 首先会将整个 nanos-lite.bin 加载到 0x80000000,而 nanos-lite 又会将 naive_uload(NULL, proc_name); 所指示的程序,按照其 elf 文件的指示,加载到对应的内存位置,随后跳转执行。
nemu 加载 nanos-lite.bin 的过程,直接忽视了 elf 文件的加载指示。这是为了在 PA3 不支持虚拟地址的情况下,避免冲突?
Navy 应用的三种运行方式:
- 在 navy/apps/app/repo 下
make run:完全运行于真机上,但不是所有的应用都支持。 - 在 navy/apps/app 下
make ISA=native run:使用 navy-apps 中的函数库,但系统调用由真机处理,libc 也是真机上的 libc。 - 在 nanos-lite 中
make ARCH=native run:将 nemu 替换为真机。 - 在 nanos-lite 中
make ARCH=riscv32-nemu run:完全运行于 nemu 之上。
libos:native与nanos-lite的折中
在从我们的实现转换到 native 时,不同于 libc 的直接替换,libos 并没有直接调用真机提供的 _open() 、_write() 等函数,而是首先在 native.cpp 中覆盖了 open() 、write() 等高级库函数,在其中再去调用 _open() 、_write()。那么,native.cpp 重写了哪些内容?以 write() 为例:
ssize_t write(int fd, const void *buf, size_t count) {
if (fd == sbctl_fd) {
// open audio
const int *args = (const int *)buf;
assert(count >= sizeof(int) * 3);
SDL_InitSubSystem(SDL_INIT_AUDIO);
SDL_AudioSpec spec = {0};
spec.freq = args[0];
spec.channels = args[1];
spec.samples = args[2];
spec.userdata = NULL;
spec.callback = audio_fill;
SDL_OpenAudio(&spec, NULL);
SDL_PauseAudio(0);
return count;
}
return glibc_write(fd, buf, count);
}可以发现,其主要重写了对于 /dev/sbctl 的写入过程,而 /dev/sbctl 这个文件在真机上是不存在的。因此,在切换到 native 时,libos 需要添加一层转换,来消除 nanos-lite 与真机间的差异,例如文件定义的差异、路径的重定向等。
Debugging
抑制自己叙述 debug 经历的方法:
- 折磨你许久的 bug,别人可能一眼就能看出来
- 你捋清了来龙去脉,但无法避免下次仍然会犯类似的错,进行类似的 debug。所以,只记录对自己 debug 能力有提升的过程。
关于正向与反向 debug 的思考:所谓反向,即一路 printf,通过程序的反馈定位到出错的具体 API,然后检查实现的错误。这种方法针对性强,但在对付较大程序时,通过 printf 定位就要花费很长时间;同时,printf 只能定位到 bug 导致 abort 的位置,这可能与 bug 产生的位置相去甚远(例如指针被修改,导致后续访存错误)。前者可以通过 gdb 来解决,后者也可以通过 gdb 对内存、变量进行监视来解决,不过需要对出错的可能性进行初步的猜测。而所谓正向,即直接对着自己的实现查找不合规范/错误的地方,这种方法只适用于实现内容较少、剩余内容保证正确的情况。
nplayer在nemu上播放时的卡顿现象
expand to see debug process
起源:打印 nemu 中 SDL 回调函数的情况(nemu 中的 SDL 最终会播放音频),可以很清晰的观察到卡顿与以下情况的对应:
nemu audio wants 16384, sbuf has 16384 nemu audio wants 16384, sbuf has 16384 nemu audio wants 16384, sbuf has 16384 nemu audio wants 16384, sbuf has 8192 nemu audio wants 16384, sbuf has 24576 nemu audio wants 16384, sbuf has 24576在am-test中播放,发现很流畅,并且sbuf一直都是满的。每次SDL回调获取,对应着nemu写入4次,每次4096,速率刚好对应上。
nemu audio wants 16384, sbuf has 65536 Already play 15601664/45551184 bytes of data Already play 15605760/45551184 bytes of data Already play 15609856/45551184 bytes of data Already play 15613952/45551184 bytes of data nemu audio wants 16384, sbuf has 65536 Already play 15618048/45551184 bytes of data Already play 15622144/45551184 bytes of data Already play 15626240/45551184 bytes of data Already play 15630336/45551184 bytes of data上述完美的对应关系启发我在nanos里也对缓冲区写入进行了监视:
nemu audio wants 16384, sbuf has 16384 nanos sb_write 8192 nanos sb_write 8192 nemu audio wants 16384, sbuf has 16384 nanos sb_write 8192 nemu audio wants 16384, sbuf has 8192 nanos sb_write 8192 nanos sb_write 8192 nemu audio wants 16384, sbuf has 16384 nanos sb_write 8192 nanos sb_write 8192 nanos sb_write 8192
成因:音频数据通过 SDL
暂时的解决方法:如果在 CallbackHelper 中将执行 NDL_PlayAudio() 的间隔阈值降低, 使得音频数据在缓冲区中冗余,就不会因为数据不足导致卡顿了。虽然缓冲区写入端比理论速度快,但这并不影响播放端读取的速度(这对应 nemu 中运行于真机上的 SDL_Audio ),因此播放的效果是一样的。
一个问题:为什么在native上不会出现上述问题?我能想到的解释是:在nemu上运行时,本质上还是一个串行程序。在native中正常,说明回调函数的调用其实是及时的,但如果底层是nemu,其中的运行逻辑会导致回调函数的执行间隔增加。
void CallbackHelper() {
if (pause || !spec) return;
uint32_t cur_time = NDL_GetTicks();
if (prev_time == 0) prev_time = cur_time;
int coeff = 1;
#if defined(__ISA_RISCV32__)
coeff = 2; // add for nemu
#endif
if (cur_time - prev_time >= 1000*spec->samples/(spec->freq*coeff)) {
/* call audio callback and playaudio here */
}
else return;
}nplayer 的错误显示
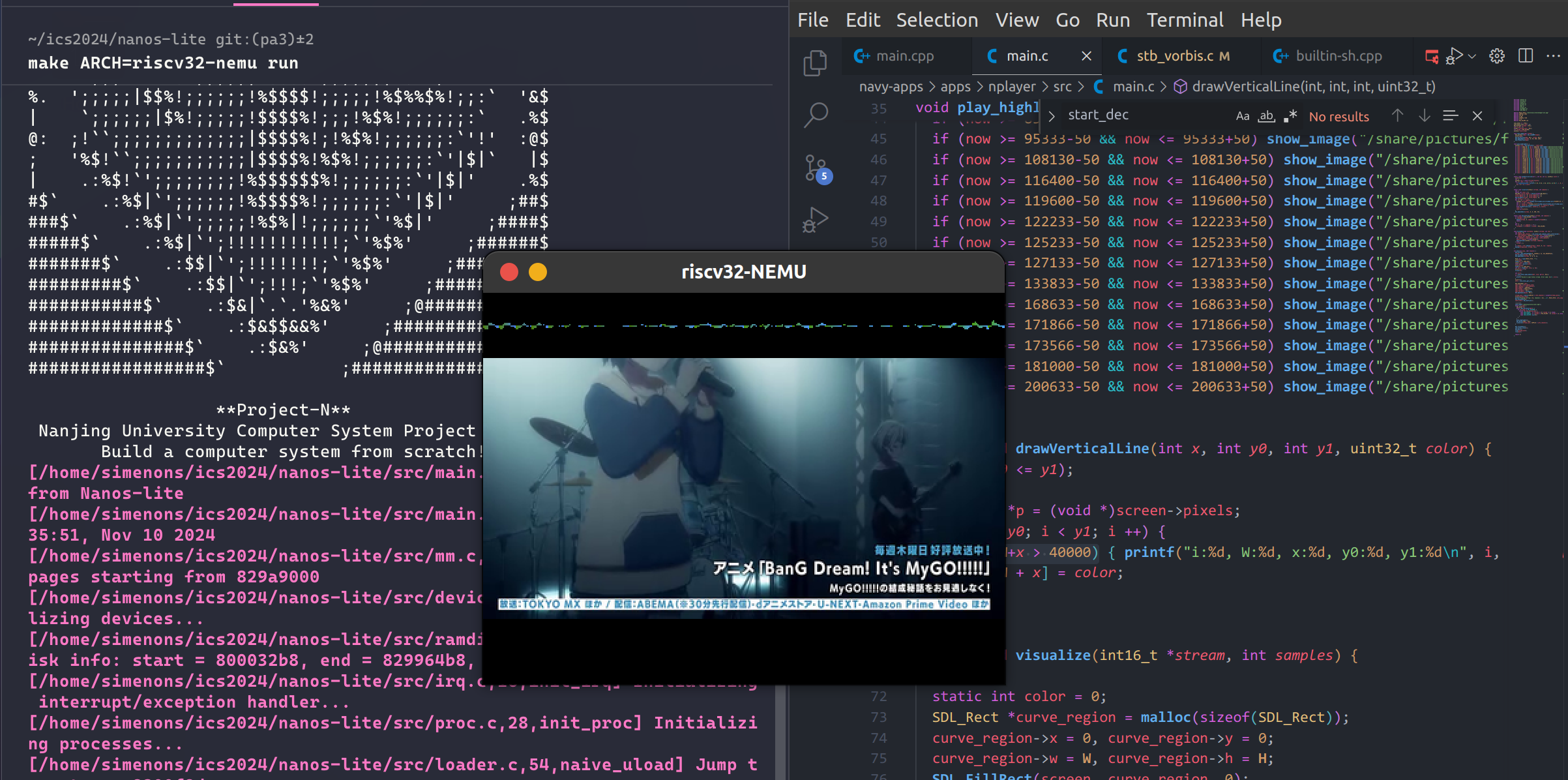
如图所示,nplayer 的音频可视化左半边正常,但右半边异常。查看 nplayer 源码可以发现,是由于 visualize(int16_t *stream, int samples) 时,stream 中只有 samples / 2 个样本。

记初始化得到的音频信息 SDL_AudioSpec 为 spec,nplayer 每次调用 visulize 的参数如下:
- stream:是 nplayer 自己维护的一个 stream_save 缓冲区,其中的内容为上一次执行
spec->callback获取到的音频数据 - samples:每次要可视化的采样样本数,nplayer 恒定传入
spec->channels*spec->samples。
回顾 SDL_Audio 的回调函数 void callback(void *userdata, uint8_t *stream, int len) ,每当 SDL 判定需要获取新的数据时,就会调用该函数,来请求向 stream 中写入 len 字节的音频数据。对于给定的音频,单位时间内播放的数据量是固定的,但是其请求的频率,以及相应的每次写入的字节数,并没有明确指出。STFW,并结合 spec->samples 的含义,SDL 每次执行回调应该会获取 spec->channels*spec->samples*sizeof(int16_t) 字节的数据,而 visualize 实际获取到的是这个数值的一半。将 nplayer 编译到 native (SDL1.2和基于浮点数运算的 libvorbis),发现也是如此。(这不禁让我认为是 nplayer 实现的问题,甚至一度准备开 PR)最终,发现这两种运行方式下,问题各自如下:
native:注意到 native 基于的是 SDL1.2,而 PA3 要求实现的是 SDL2。二者对于
SDL_AudioSpec的定义略有不同。expand to see SDL_AudioSpec definition for SDL1.2 and SDL2
SDL2
typedef struct SDL_AudioSpec { int freq; /**< DSP frequency -- samples (each channel) per second */ SDL_AudioFormat format; /**< Audio data format */ Uint8 channels; /**< Number of channels: 1 mono, 2 stereo */ Uint8 silence; /**< Audio buffer silence value (calculated) */ Uint16 samples; /**< Audio buffer size in sample FRAMES (total samples divided by channel count) */ Uint16 padding; /**< Necessary for some compile environments */ Uint32 size; /**< Audio buffer size in bytes (calculated) */ SDL_AudioCallback callback; /**< Callback that feeds the audio device (NULL to use SDL_QueueAudio()). */ void *userdata; /**< Userdata passed to callback (ignored for NULL callbacks). */ } SDL_AudioSpec;SDL1.2
freq Audio frequency in samples per second format Audio data format channels Number of channels: 1 mono, 2 stereo silence Audio buffer silence value (calculated) samples Audio buffer size in samples size Audio buffer size in bytes (calculated) callback(..) Callback function for filling the audio buffer userdata Pointer the user data which is passed to the callback function对比发现,SDL1.2 中对于 samples 的定义并不是单声道的采样大小,而是总共的大小。因此,每次回调只会获取
spec->samples*sizeof(int16_t)字节的数据。navy:
其实是 bug:计算间隔时,
spec->channels错误的写在了分母,而计算字节数时,又没有乘上单个样本的大小sizeof(int16_t)二者刚好抵消,最终的效果是数据写入速度正确,但每次写入的字节数减半。if (cur_time - prev_time >= 1000*spec->samples/(spec->freq*spec->channels)) { int query_len = spec->channels*spec->samples; int free_space = NDL_QueryAudio(); query_len = free_space < query_len ? free_space : query_len; spec->callback(NULL, (uint8_t *)SDL_AudioBuf, query_len); // len is the desired bytes NDL_PlayAudio(SDL_AudioBuf, query_len); prev_time = cur_time; }
libfixedpt 精度问题
没有检查(拿出错计算,一步步查找是否为实现错误)是否为 libfixedpt 的实现问题,如果是,那就糗大了。
libfixedpt 致错的原因很简单:精度不够,导致计算结果误差过大。但是导致的 bug 就不太友好了。
首先是 start_decoder() 中对于 ogg 音频的初始化,在 lookup1_values() 中,int r = fixedpt_toint(fixedpt_floor(fixedpt_exp(fixedpt_divi(fixedpt_ln(fixedpt_fromint(entries)), dim)))); 的误差会导致初始化失败。通过打表解决。
然后是音频播放到3分钟左右时,会直接 Segmentation fault(稳定在“照らされた世界 咲き誇る大切な人”,导致我一下午几乎完整地听了50多遍春日影)。debug 的尝试过程过于冗长,这里就略去了。总体而言,就是先通过 gdb 和 printf 找出是 codewords_length[var] 时出错,随后判断是该数组地址被非法修改(主要的尝试过程);基于此,直接在 gdb 中 watch v->codebooks->codewords_length 即可找出是在 drawVerticalLine() 中被修改。那么,这个修改是否合法呢?打印发现,这里的访存下标超出了 pixels 申请的大小,所以是非法的。 发现问题后,首先尝试了将 i <= y1 修改为 i < y1 ,发现不再触发 assert。1位的差距,基本可以断定,这又是浮点数计算误差的锅。
static void drawVerticalLine(int x, int y0, int y1, uint32_t color) {
assert(y0 <= y1);
int i;
uint32_t *p = (void *)screen->pixels;
for (i = y0; i < y1; i ++) {
assert(i*W+x <= 40000);
p[i * W + x] = color;
}
}感想
完成过程比想象的慢不少,但二周目还是有不少收获。
首先是对于抽象层的理解。哪怕现在还是不能记清中断处理过程经过了哪些函数,但是,能够很清楚的知道,abstract-machine、nanos、navy 究竟对应了实际计算机系统的哪些实体/抽象概念。一周目虽然也在讲义的引导下,知道了计算机有哪些抽象层,但一被问到:make ISA=native run 用到了哪些真机 API、nemu 的内存布局是怎样的这种细节,nemu 音频卡顿该从何debug起,就完全没法回答了。事实上,如果对一个程序在计算机上编译、运行的过程了解足够,那么 PA 中的抽象层几乎是水到渠成的。
其次是对于编译、链接过程的了解。一周目往往是对着讲义运行程序,在 navy 中添加一个 -g 选项甚至都要思考。但在二周目中,由于被迫读了 Makefile,对整个 nemu 生成的过程了解拓宽了很多,有了 Makefile 的信息,对于理解编译链接过程、对于理解抽象层,都有很大的帮助。
最后是 debug 技术的长进。其实就是多使用了 gdb 这一趁手工具,在上述的反向 debug 时能减少很多工作量。