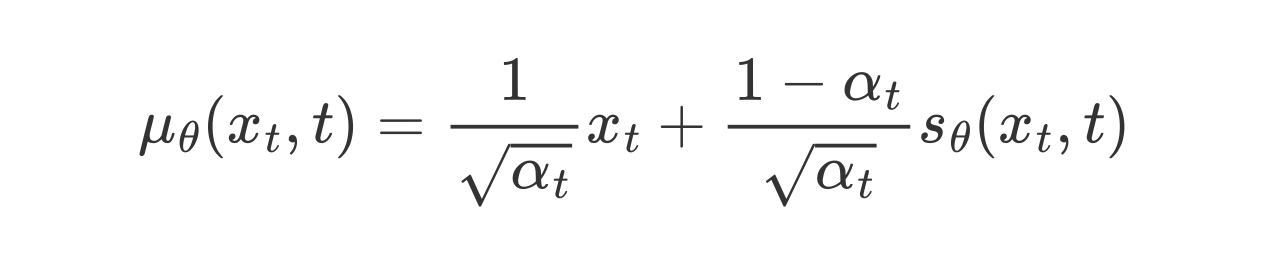
DMs[4] DDIM
DMs[4] DDIM
从最基本的联合分布等式,给定条件,可以略去部分条件项,写成不同的形式,而这些形式代表了前向/后向过程:从数学表达式上讲(回归到原始的联合分布来理解),表明了如何一步一步得到联合分布密度;从生成
讲(使用化简后的形式),可以将联合分布的求积项拆分成若干次采样(因此,在跳步采样中,可以看到有若干项与前向/后向过程是无关的,所以可以去除)。 为什么要写
和 ??考虑整个过程,我们想要得到的其实是 而对于
的极大似然的 ELBO,正是这两个联合分布的 KL 散度。逆向过程是我们来建模的,所以我们的 形式可以与 尽可能相似。(corresponding)
存在的问题:逆向过程和正向过程是绑定的,而正向过程需要很多步,所以逆向过程也需要很多步。
DDPM的损失函数:
可以发现,这个损失函数只依赖于
定义,证明边缘分布,证明损失函数
基础等式,恒成立:
在 DDPM 中,前向过程是一个马尔可夫过程,
而在 DDIM 中,作者考虑了具有如下形式的一族分布:
其中
到这里,我们知道了这个分布的逆向转移核,当然正向转移核(不再是马尔可夫过程,不过也不再需要知道)也可以直接由贝叶斯定理得出:
这个分布的推导过程可见这篇文章,总结来说:我们需要根据
和 不变的假设,求解 。由于没有了前向过程的限制,最终解出的是一族分布。至于为什么要写成 的形式,可能因为这个表达式作为逆向过程的拟合目标? 以及,在得出对应的逆向过程时,文章"leverage the knowledge of
", 也就是直接认为 应该拟合 。(其他文章甚至是一开始就这样以重新表达 为目标)这一项实际上是来自于 ELBO 的推导。
接下来就是定义可训练的逆向过程,使得
我们就可以利用
到这里,我们还有最后一个问题没有解决:这个新定义的分布,其损失函数能否写成【】的形式?依然从极大化观测样本
【ELBO】的前几步
作者证明了可以将这个式子写成
采样
定义
可以看作3项:
- 预测
- 指向
- 随机噪声
当
DDPM
回忆在 DPM 推导中,我们直接令逆向过程的方差为高斯分布
【】中的随机噪声项被置零,整个采样过程变为一个确定性的过程,作者把这种特殊情况称为 DDIM (denoising diffusion implicit model)
- denosing diffusion:用的是 DDPM 的训练目标函数(实际上也是在往上面靠)
- implicit model:是一个 implicit model【?】
加速采样
通过跳步,DDIM 可以实现加速。这篇文章 给出了更加直观的解释。
原文的解释中,暂时无法理解如何得出 "corresponding" 的生成过程形式。