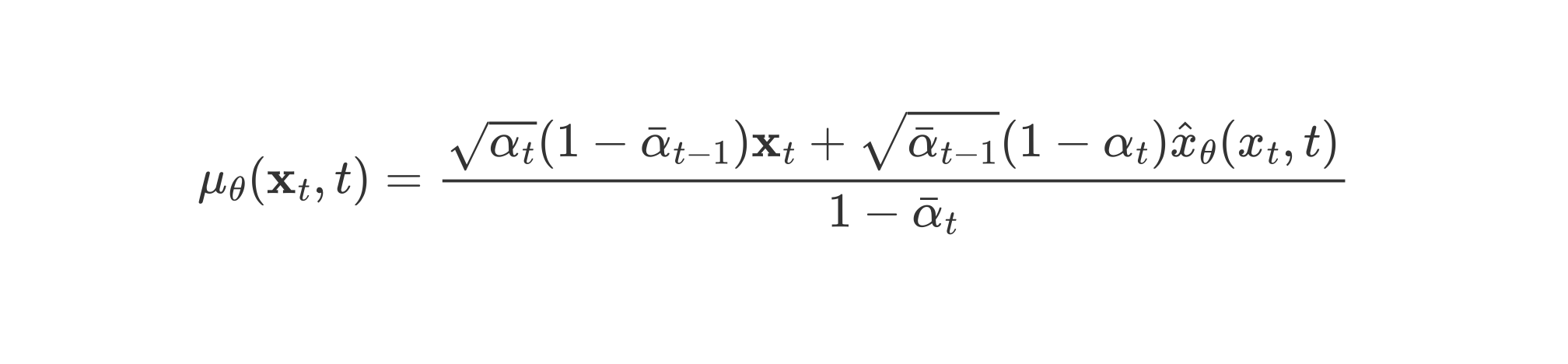Figure 1: Architecture of VDM.
Figure 1: Architecture of VDM.VDM 的原理与 MHVAE 非常类似,可以看作是在 MHVAE 的基础上添加了如下 3 个限制条件得到:
- 隐变量 的维度与输入输出 的维度一致。因此,不再使用 ,而统一使用 来表示所有的变量。
- 编码器 不再是通过神经网络学习的过程,而是一个固定的高斯线性变换。
- 通过为编码器的一系列高斯线性变换设置系数,使得最终的 收敛到 。
前向过程
给定一个真实输入 ,通过逐步添加噪声,最终得到 ,因此也叫作扩散过程。整个模型的后验分布可以写作:
而由于编码器不再是一个参数化的过程,所以 可以用公式明确给出:
逆向过程
从随机高斯噪声 开始,逐步还原出有意义的数据。整个模型的联合概率可以写作:
其中,根据模型假设,我们知道 。那么,我们能否直接给出 的表达式呢?
观察其中的各项:
- :该项是前向过程的加噪过程,可以写出表达式;
- :该项表示了 时样本的边缘概率密度函数,可以从 迭代计算得到。但 对逆向过程来说不可知(即便是通过采样来模拟);
- :该项表示了 时样本服从的概率密度函数,需要对 的各种取值进行遍历积分,对于图像来说,这显然不可行。
因此,我们没法直接给出 的表达式。而扩散模型借助参数化近似(如神经网络)来学习逆过程分布。
另一种想法是,基于 (2),对其进行重参数化,可以得到:
移项之后,不就可以得出 了吗?
这里搬一下 路橙大佬的解答,(目前get的)大致意思是:高斯分布对应的重参数化结果 中,这两个变量应当是相互独立的,而反解结果中, 与 不再独立,所以即使写成了重参数化形式,也不能逆推回高斯分布。而这里的 也是具有实际含义的,它就是 DDPM 想要预测的噪声
VDM 可以通过最大化 ELBO 来进行优化:
最终得到的 ELBO 由如下 3 项构成:
:重建项,其含义同 AEs 中的重建项,表示了给定一步扩散过程的情况下,模型重建出原始输入 的能力。
:先验匹配项,其含义同 AEs 中的先验匹配项,表示了前向过程 得出的 分布与其先验分布 的匹配程度。但是,由于这一项不含可学习的参数,再加上当 足够大时,,这一项自然为0,所以并不需要对其进行优化。
因为当 足够大时,,所以无论 取值为何, 都趋向于
:一致项,使得前向过程由 生成的 和逆向过程由 生成的 的尽可能相似。
 Figure 2: Depiction of consistency term.
Figure 2: Depiction of consistency term.
如果对 这种形式的期望的实际含义感到困惑,那么就先看看 AEs 中的相关解释吧。实际上, 可以通过随机采样来模拟。
因为最终 ELBO 中待优化的项都是期望的形式,所以可以通过 MCMC 近似求解。但是,如果直接对 (5) 中的式子进行优化,可能会导致困难。因为其中的一致项需要同时对两个随机变量 进行采样,这会产生更大的方差,导致优化过程不稳定,不容易收敛。
由于 VDM 的马尔可夫特性,有 ,再通过贝叶斯定理,有:
将(6)式代入 ELBO 的推导,可得:
expand to see detailed derivation
可以不会推导,但至少要能看懂吧
其中值得注意的是倒数第二步,实际上用到了如下性质:
最终得到的 ELBO 由如下 3 项构成:
:和 (5) 相比没有变化。
:和 (5) 相比在形式上略有区别,对于前向过程 得到的 ,此处是由 直接得到,而在 中,是先由 得到 ,再得到 。但含义相同。
最后一项中,需要采样的变量只剩下 一个了,其实际含义是使得模型建模的 与真实分布 尽可能接近。
虽然 表示的是正向过程,而用 来表示逆向过程,表示的是直接由正向过程计算得到的逆向过程,即逆向过程的真实分布。
而条件项 的加入也很符合直觉:作为 gt,其降噪步骤必然与原始输入 相关。并且,在 (4) 式中尝试给出逆向过程的表达式时,也发现其依赖于 。
接下来就是代入计算,第二项不含可学习的参数,可以直接忽略。
首先来表达确定的 。由贝叶斯定理,我们可以将其写成如下形式:
由模型的马尔可夫性质,我们知道 。而 呢?到目前为止,我们只知道能够通过迭代求出它们的值,但事实上,同样可以显式给出它们的表达式:
expand to see detailed derivation
简单的展开
然后,我们就可以将这三项代入 中进行化简:
expand to see detailed derivation
由此,我们发现由 得到的 其实服从于 。而 KL 散度中的另一项呢?是模型决定的 。要使得 与 尽可能接近,索性也让其是一个高斯分布。
- 对于方差,由于 只和时间步 相关,逆向过程的模型也可以获取到该值,所以索性令 的方差也是 ;
- 对于均值,就不能这么干了,因为 与 相关,逆向过程的模型无法获取到该值,因此必须通过参数化求解,不妨设当前的均值与 和 相关。
综上所述,我们约定了 ,而两个高斯分布的 KL 散度又是有公式的:
因此,可以得出真实分布 和参数化学习分布 的 KL 散度为:
极大化 ELBO 函数,等价于极小化 (12),等价于使得每个时间步,模型的 与 真实分布的 尽可能接近。于是,我们又可以索性令 与 具有相似的形式:
换言之,模型只需要预测其中的 。于是乎,我们可以进一步简化 (12) 中的极小化目标:
相对 denoising matching 项来说,这一项并没有涉及很多的求和项,所以对于逆向过程模型的假设都是以 denoising matching 项分析中的“索性令”为准。
多元高斯分布的概率密度函数为:
据此化简 reconstruction term:
又因为 需要用到 ,这个值并没有定义(事实上在 denoising matching 项中, 的下界也是 2),这里我们不妨另其为 ,则可以进一步将优化目标写作:
为什么这么写,接下来就会明白了
结合以上两项的结果,我们可以得出最终的优化目标:
从目标函数中可以发现,模型在每个时间步 都在预测原始输入 ,而推理过程却是使用 来计算 ,从而结合 计算出 ,最终随机采样得到 。通过 步采样得出最终的输出。直觉上讲,每一步预测的 目标按道理是不同的。
After reading
经过如此冗长的推导,我们不妨来回顾一下整个过程:
- 生成过程是基于一个 MHVAE;
- 因为前向过程确定,我们实际上要学习的是从 这个先验高斯分布,采样还原出 的逆向过程 ;
- 采用 MLE 进行学习,可观测的生成样本只有 ;
- 经过一系列推导,得出目标函数中的若干项,其中高斯分布极大简化了推导过程;
- 因为目标是最小化损失函数,因此我们可以令 具有和已知概率密度函数相似的结构,而将无法直接获取的部分留待网络学习;