毕设
毕设
- 填暑假前的坑
- 有些东西没法写在毕业论文里。趋近于零的贡献硬是被扩成了几十页又臭又长的论文,隔一段时间再看,可能自己都找不到其中真正有效、真实的信息。同时,相比于其他更为夸张的毕业论文撰写过程,这篇毕设还算是对我自身的进步有一定价值。食之无味,弃之可惜,故另写一篇 blog 记录一下。
起因
最初的最初,拿到的任务是优化 SD 以控制内存消耗在 800 MB 以下,搜集一番之后,发现这一方向的论文并不是很多,更多的是一些库中的优化选项(比如 unet.enable_xformers_memory_efficient_attention())以及一些需要结合扩散模型实现细节,对原始实现进行手动优化的 tricks(比如 这篇 blog),实际上 SD 模型的四个组件、内存开销的来源都是从这篇文章中了解到的)。当时面临两大难题:
- 对 Diffusion 架构并不了解,对于其中的 Attention、ResNet 模块可谓是听得云里雾里,也不知道整个去噪过程是怎样的,更不要提优化了;
- 对实现细节不了解,HuggingFace 上的 demo 以及论文仓库里的示例 demo 大多使用
Unet2dConditional.from_pretrained()这种高度封装的 API,完全不知道该如何修改其结构。
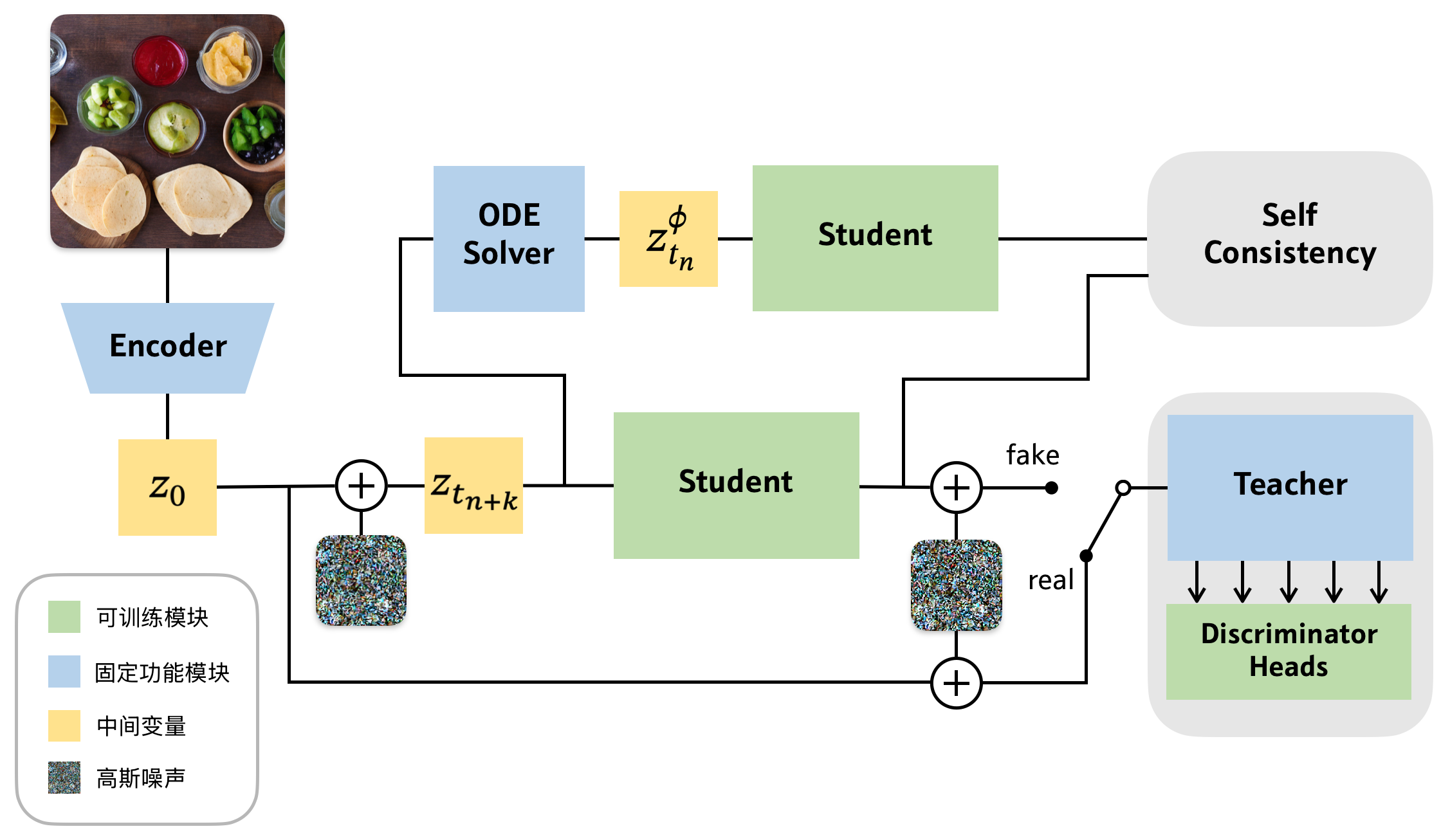
所以转头开始从头学起扩散模型,该课题就一直搁置着。后续看完了基础的扩散模型后,自然而然的就顺着推荐转到了 DDPM、DDIM、Analytic-DPM、DPM-Solver 这一系列理论工作,相较于内存优化,扩散模型加速领域的工作非常多,因此看得不亦乐乎。直到学期末时,看到了 SANA 这篇工作,对 4 个组件都有相应的优化(简介可见这篇总结),很符合之前的认知,因此准备将其作为 baseline 去完成毕设。寒假期间并没有思考该在此基础上做哪些改进,直到开学后,搜索扩散模型加速算法时,找到了 LCM 这篇工作,打开了 distillation 的大门。蒸馏非常适合进行 A+B 式的糅合,至少对于毕设来说是一个足以成文的 idea。但在复现这一步就出了问题,web 数据集 laion-aesthetic 首先就比较棘手,再者由于训练资源的不足,随后的复现标准也一降再降:从一开始要求在不同 guidance scale 下逼近原论文的 FID,到要求 FID 数量级一致并且随着 guidance scale 变化趋势一致即可,再到去掉 guiding distillation,固定 guidance scale 进行训练...... 论文的目标也从“将 LCM 迁移到 SANA 上”,变为了“解决低训练资源下,LCM仍存在的问题(即使这个问题在原论文并不存在)”。
这就是毕设的前世今生。
实际的改进
那就对着毕设一条条说吧
文本编码器语义增强
LCM 为 base,但低训练资源下效果不佳,加入了 VLM、LLM 做语义增强
对数据集应用 VLM 修改 caption 的确能够大幅提升 CLIPScore、FID 这些指标,但训练结果提升并不显著;
LLM 部分,SANA 中是直接替换了原本的 T5 编码器,但是由于内存限制,实际采用的是 offline 的形式,对于训练数据和测试数据,提前先用 LLM 输出 raw text,再作为 prompt 输入原本的编码器。这种做法本质上就没什么道理,用 LLM 作为文本编码器就是取其输出 text embedding 的特异性,修改为“更为丰富”的 prompt 显然没法做到。并且,LLM 增强后的 prompt 其实 CLIP Socre 会大幅下降(比如单辆跑车的照片,会 yy 成若干跑车依次排列的场景)。这一点是后续发现的,所以在后续的训练中可能并没有使用 LLM 对训练数据进行处理,而在测试时保留了 LLM 增强。所以结果可以略过。
"指标还是全都用 llm-gen 测试(包括 base,这是用了 llm 的 base)"
动态噪声调度
进一步加入判别器损失,并且采用均匀分布的噪声采样,但效果反而变差,因此引入了噪声调度,最终相比不使用判别器损失的 base 效果提升;
其实这是最扯的一点,因为噪声调度一直是和判别器损失捆绑使用的,使用判别器损失的[论文][LADD, SANA-sprint]都会附上最优的噪声调度方式。论文这里的做法实际上是先不用噪声调度,均匀采样时间步(甚至由于误解,取了
的低噪声),然后再使用别人确定的 噪声调度,实现效果的提升,而自己提出的 dynamic 其实也没有真正实施。
噪声调度(noise schedule)一般指的是扩散模型 forward 过程中
LADD 的结果显示,一个固定的,偏向较大时间步的噪声采样策略就足以提升图像整体的一致性。这一点复现出来了,但 dynamic 实际上没有测。超参嵌套超参,其实没啥必要实验了,非常微不足道的一个 trick。另外,从
判别器头结构
魔改判别器头的结构
FFT 的加入确实提升了指标,但并没有通过 output 进行对比;attn 同上,训练受限,效果不升反降。
通过 FFT 分离高低频信息分别处理是一个较为常用的方法,但用在这里其实也有超参嵌套超参的嫌疑:因为输入判别器之前的噪声调度实际上已经在分离高低频信息,供判别器分别学习了。
一些有价值的内容
实际上有价值的内容并不在贡献部分
- 相关知识、相关工作中对扩散模型的前向、逆向过程,三种等价模型,SDE、PF-ODE 的来由等进行了梳理,理清了“为什么要预测
- LCM 的 distillation 框架值得仔细琢磨,后续 ADD(的非官方复现)、Sana_Sprint 的 train_script 都和这个框架几乎一致(虽然我记得 LCM 也是魔改而来的);
- 这个方向不适合继续做,太卷了