ForCenNet
ForCenNet
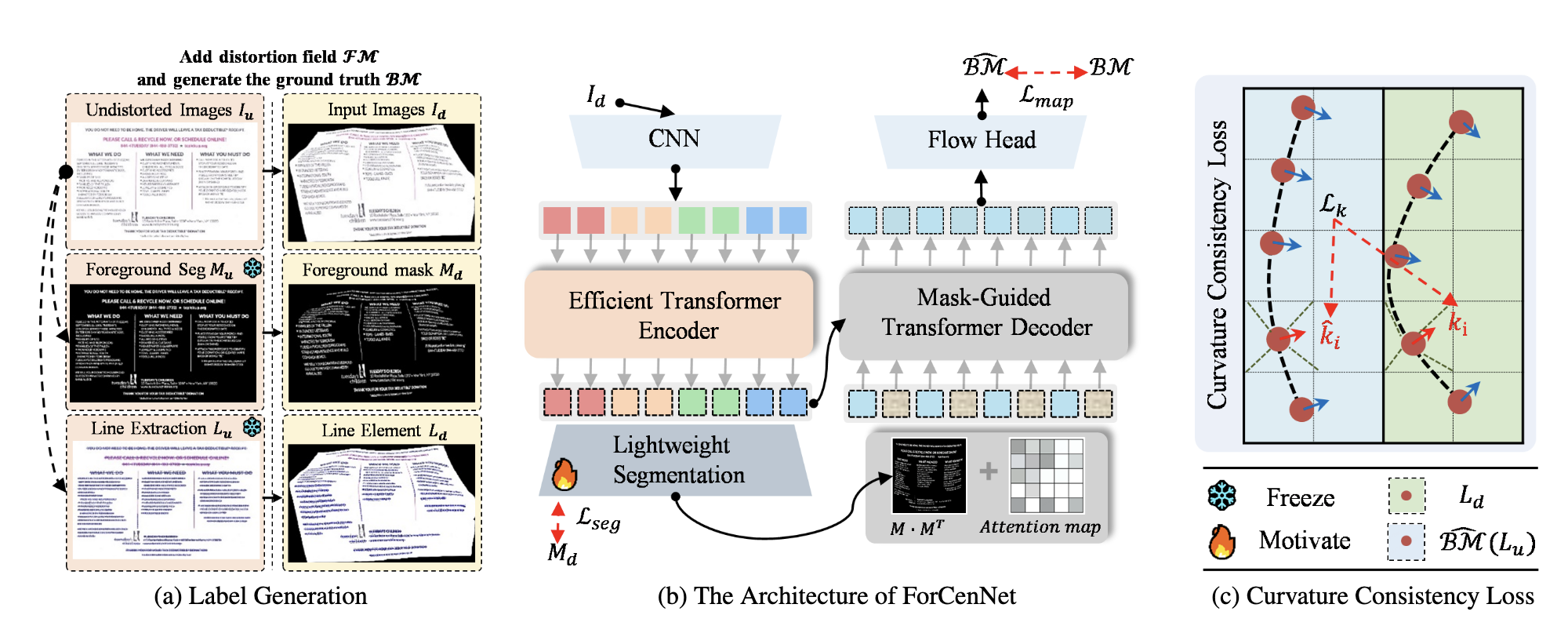
Overview
文章大概的思路是,专注于 foreground 进行还原。Foreground 指的是文档中具有明确结构的文本行、表格线等,这些是文档还原过程中的重要根据,所以可以引导模型专注于这些信息。
具体而言,文章提出了两点用于提升模型恢复文档的能力:
- 使用一个 Segmentation 网络来对 Encoder 输出进行划分。不同于 pixel-level 的划分模型,这里的输入是 Transformer blocks 编码的结果,所以只需要轻量级的网络。Transformer 的输出是序列化的?直接对序列进行划分,
- 曲率损失函数。直觉上讲,
总体网络架构上,和最原始的 Transformer 架构有些许不同的是,Decoder 并不是从 <bos> 开始自回归生成,而是以一个可学习的 embedding
复现
中道崩殂
数据集

包含了扭曲图像、扭曲图像的扫描件 alb、深度图等若干变种以及
数据集的预处理
数据集本身就已经不再维护,还是找 DocGeoNet 作者要到了一份
计算
/data1/zhangmx/workspace/doc3D-dataset-master/convert/do_it.py速度也很快,5000 samples / 7 min对
Hi-SAMSegmentation,质量堪忧;目前在尝试用fft_sharpness > 0.35来筛选样本,保留了 3291/4999 的样本,图例如下:
Figure 2: 不同 fft_sharpness 得分的样本 可以发现牺牲了 1/4 的样本,留下的仍然不是很清楚(到 0.45 以上就比较清楚,人眼基本能识别出字符),并且,这种量化方式偏好小字体的样本。但这里似乎不需要保证文本可读性,文章的训练目标是恢复扭曲文档,提高 OCR 的识别率,至于文档的清晰度,不是文章需要考虑的问题;
这一步的速度就慢一些了:5000 samples / 50 min
OCR 提取 text-lines。这里顺带测试一下文章的前提是否成立:“OCR 在扭曲文档上的识别率会下降”,事实证明是成立的

Figure 3(a): 变形文档 OCR 结果 
Figure 3(b): 恢复文档 OCR 结果 在考虑如何存储 text-lines 时,需要根据后续 text-lines 的用法来判断,但在这一步遇到了较大的问题。文章的思路大致如下:
在 original image
利用
在 distorted image 空间上,计算每个点的曲率
一阶、二阶导数用 central difference 近似,最终得到损失函数为:
这里,对于多 text-lines 的取舍、为什么会有非整数点都有待确定,暂时不太想花时间去尝试了。