InvSR
InvSR
Overview
Diffusion 用于图像超分一般有两种思路:
- Diffusion Prior for SR. 即在原本的 pipeline 上进行微调,比如通过 text prompt 或者退化类型,来指导模型进行超分;
- Diffusion Inversion. 回顾一张图片的生成过程,从随机高斯噪声
本文属于后者,且将 noise map 缩减到了
在正式开始看 Method 之前,建议先回顾一下如下几点
等价预测模型的推导
最初的起点为
通过前向过程的定义:
代入即得到噪声预测的形式
噪声项的不同含义
这里需要区分两个
跳步推理的实现
关于跳步,之前的一个疑惑是,在不同的步长设定下,为什么相同的采样公式能够得到不同的跳步结果。这里引用苏神关于 DDIM 的解读,简单来说,DDPM 的训练包含了任意子序列的训练过程,所以无需重新训练,即可在子序列上进行跳步采样;但与原本的全长序列相比,子序列的
Method
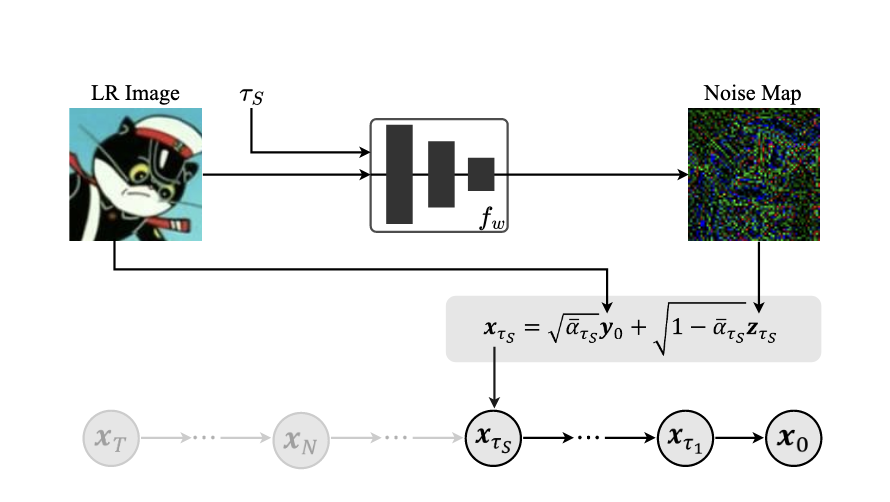
相比于最原始的 Diffusion Inversion,作者做了如下几点改进:
终点提前
理论上,终点
跳步采样
由于是 Diffusion Inversion,生成 HR 的是标准的 diffusion 去噪,所以可以沿用已有的跳步方法,例如 DDIM 等。实践中,使用
仅预测
这里原文似乎混淆了两种
,而将所有高斯噪声都用 来表示。由于具有不同的含义,例如(6) 式中表示 的噪声,而(8)表示 的噪声,实际上模型应该很难训练,毕竟这两种情形只有时间步参数的差异,因此这里对 噪声采用 记号以示区分。同时,基于 和 进行前向过程,预测 的中间状态,噪声也应该是不一样的,对于使用 计算前向过程时预测的噪声(10),记作 .
按照 Diffusion Inversion 的基本思路,我们需要预测两项:
相邻时间步采样中的噪声项
终点
至于其中的细微差别,则完全可以由网络
最终发现,需要预测的都是噪声项。有了这两项,就可以先预测
进一步,在训练中需要对齐
至此,需要预测的都是
之所以说是混用,是因为在作者的逻辑中,对
代替了基本思路中 的训练,而在 inference 中,是需要用到 “相邻时间步采样中的噪声项” 来进行迭代的,经过上述简化,就没法 inference 了。(不过最终算法里也用不到)
最后,也是和其他工作差别最大(maybe)的一点改进,作者不再预测服从标准高斯分布的
至此,noise map 被缩减到
REVIEW:
结合中间稍显混乱的设计心路历程,给人的感觉是先尝试了预测 HR 中间表示,然后逆向不预测(这是许多其他文章的缺陷),然后补上了这段故事;或者是我对模型训练的理解有问题,即:如果使用同一个网络预测,那么不同参数下的预测值的实际含义应该是统一的,而不能做到
预测 a 的年龄, 预测 b 的身高。 实际上,即使明确了这些 noise 具有不同的含义,无法使用同一个网络进行预测,依然可以得出一个通顺的逻辑:只需要删掉 Model Trainig 使得 inference 无法进行的那一段,如果截至这一段,会没发 inference,且最终算法也没用到。
To check:Model Training 中的(5)应该没有被用过?