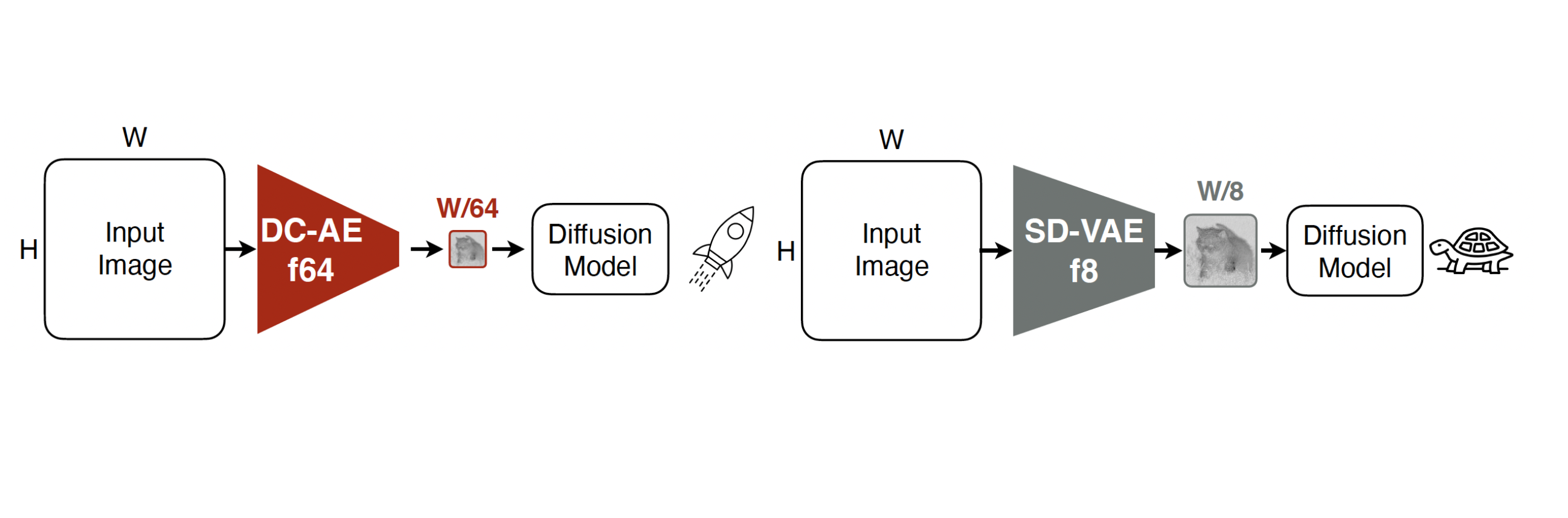
Deep Compression AutoEncoder
Deep Compression AutoEncoder
发布于 24.10
Features
- 更高的压缩率:可以将压缩率提高到
- 核心技术:Residual Autoencoding、Decoupled High Resolution Adaptation。
Methods
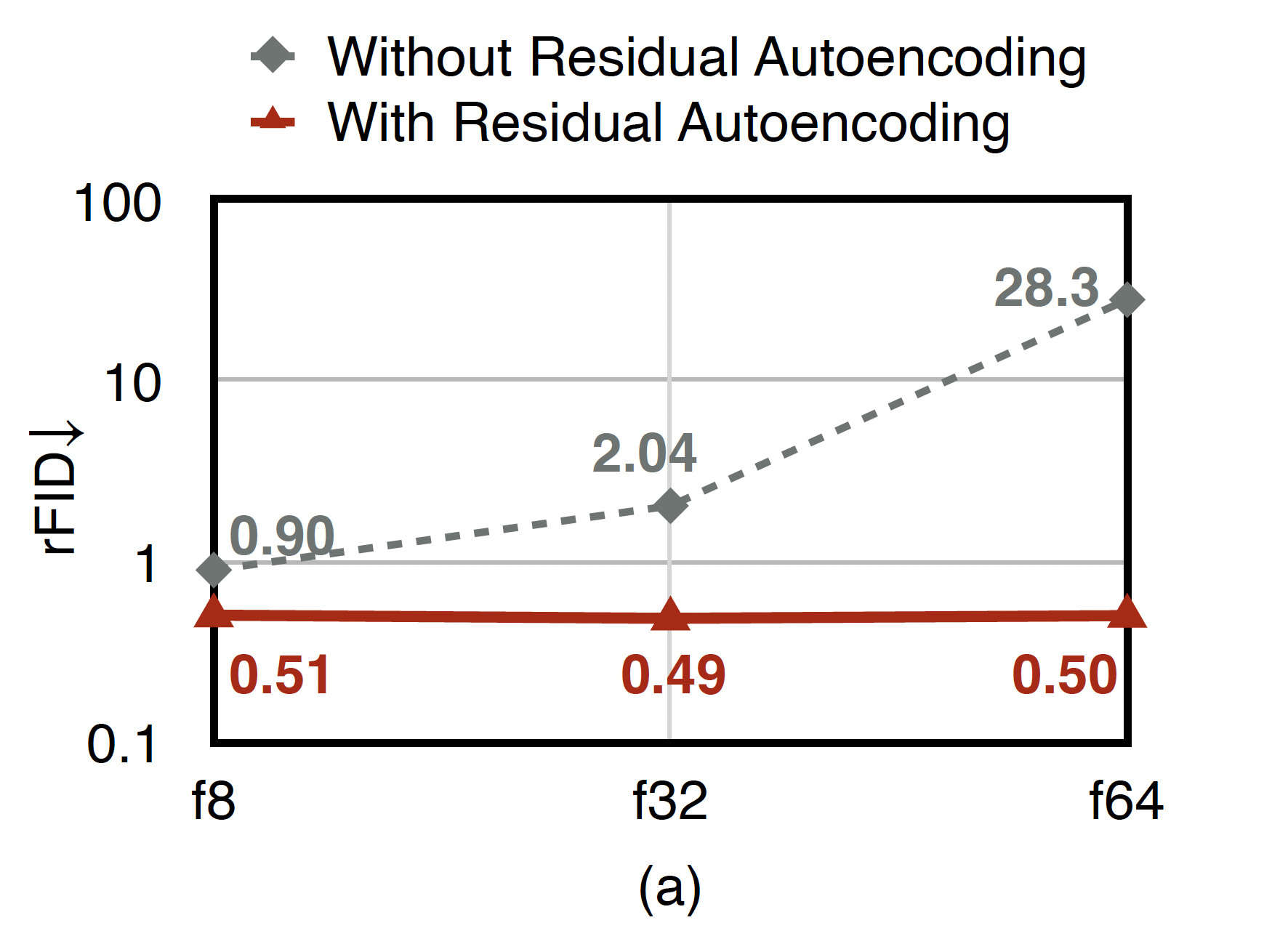
首先,进行了一组消融实验:对于 f8、f32、f64 三种压缩率,当压缩率提高时,在当前的 encoder 和 decoder 中堆叠低压缩率的 encoder、decoder,作为子网络,以提高网络的学习能力;同时,对于不同压缩率,保持 latent 的总大小一致,即
Residual Autoencoding
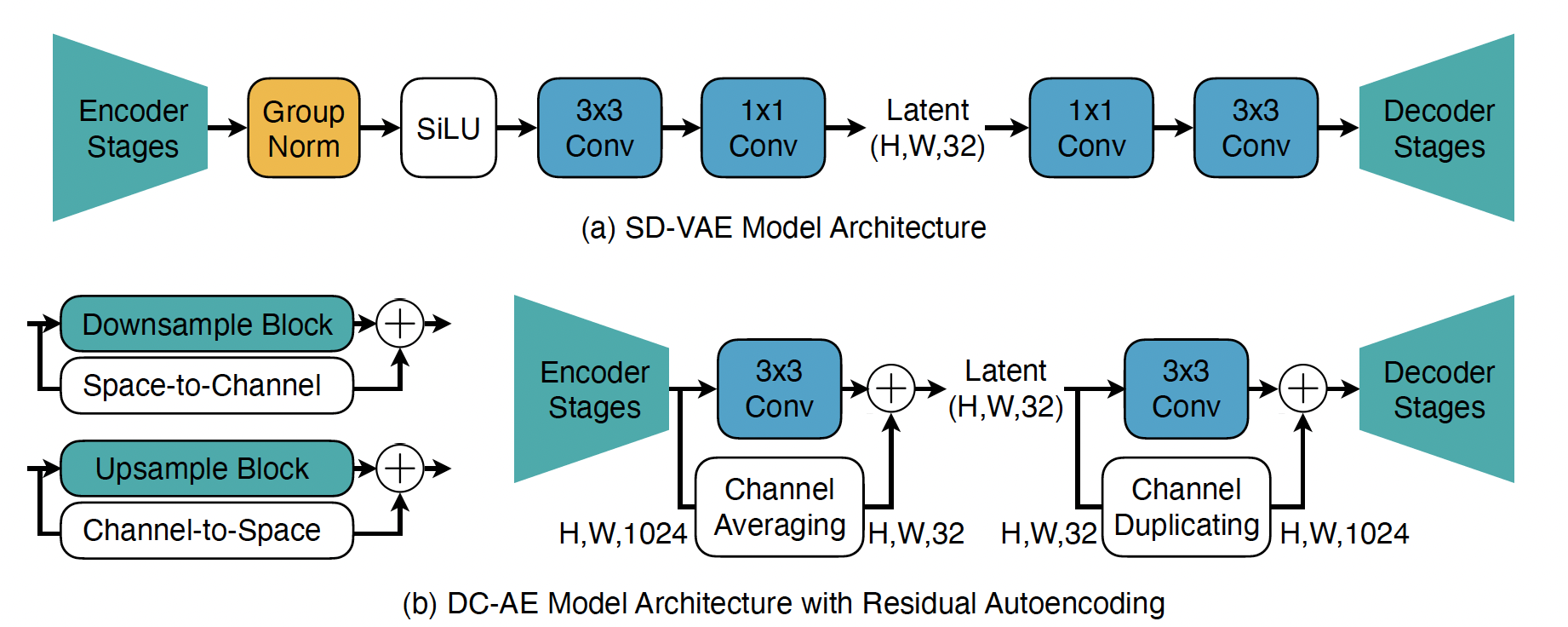
在 encoder 的 downsample block 中加入 space-to-channel 连接 + channel averaging 操作、在 decoder 的 upsample block 中加入了 channel-to-space 连接 + channel duplicating 操作。space-to-channel、channel-to-space、averaging 和 duplicating 操作都是非参数化的确定性过程。
假设一个 downsample block 的输入为
Upsample block 同理。
同时,从 Figure 2(b) 右半部分可以看出,网络的中间结构也进行了调整。
- H,W,1024 的初始 latent shape 是 DC-AE 独有的,还是SD-VAE也是如此?这是否是一个对于 channel 的压缩过程?
Decoupled High-Resolution Adaptation
注意到上述结果是在 ImageNet
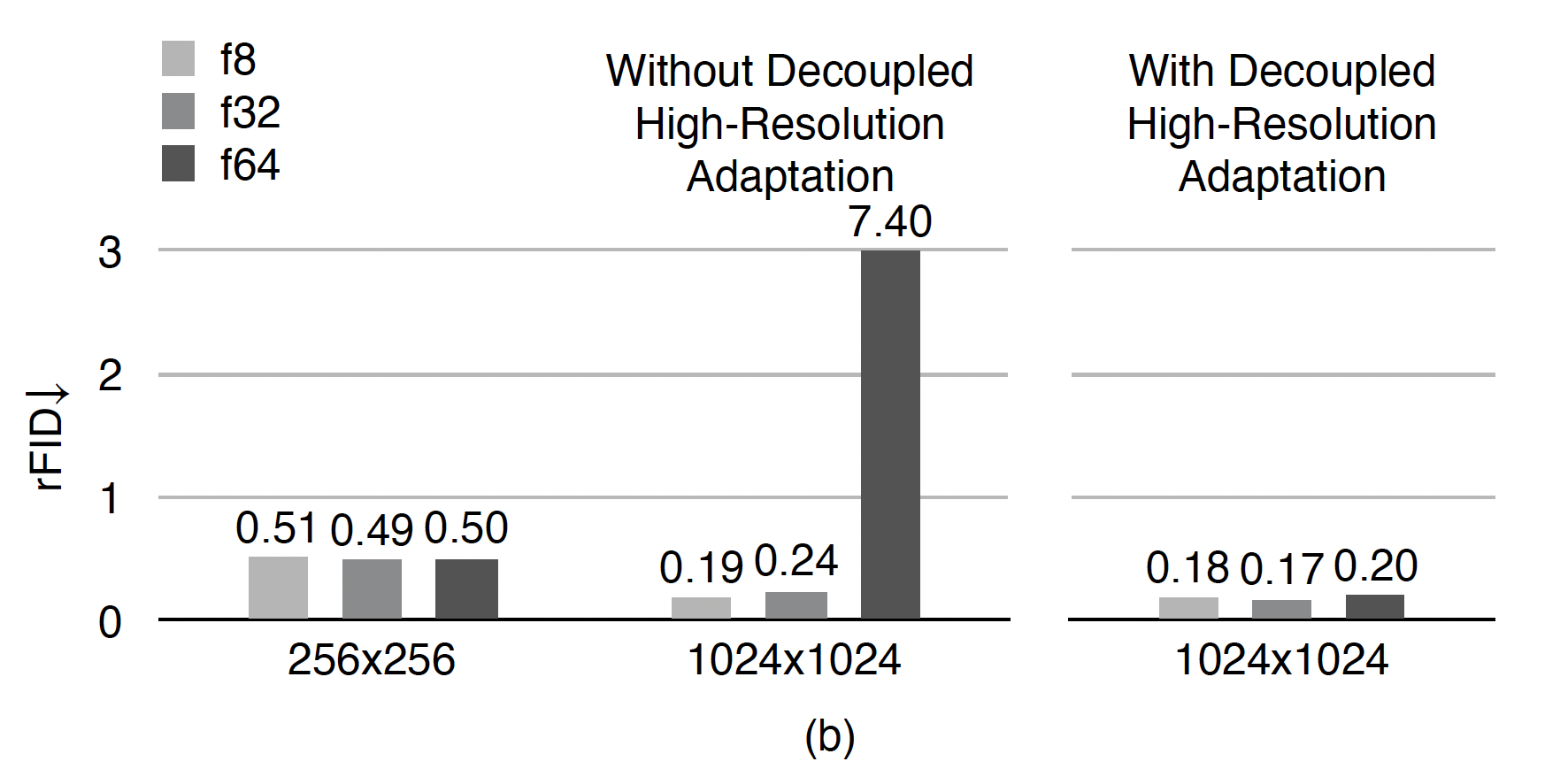
一种暴力的解决方法是直接在高分辨率图片上训练 autoencoder,但训练开销过大,并且会导致 unstable high-resolution GAN loss training。本文选择继续迁移使用 low-res 下训练的 autoencoder,但将传统的单阶段训练过程拆分成了3个阶段:
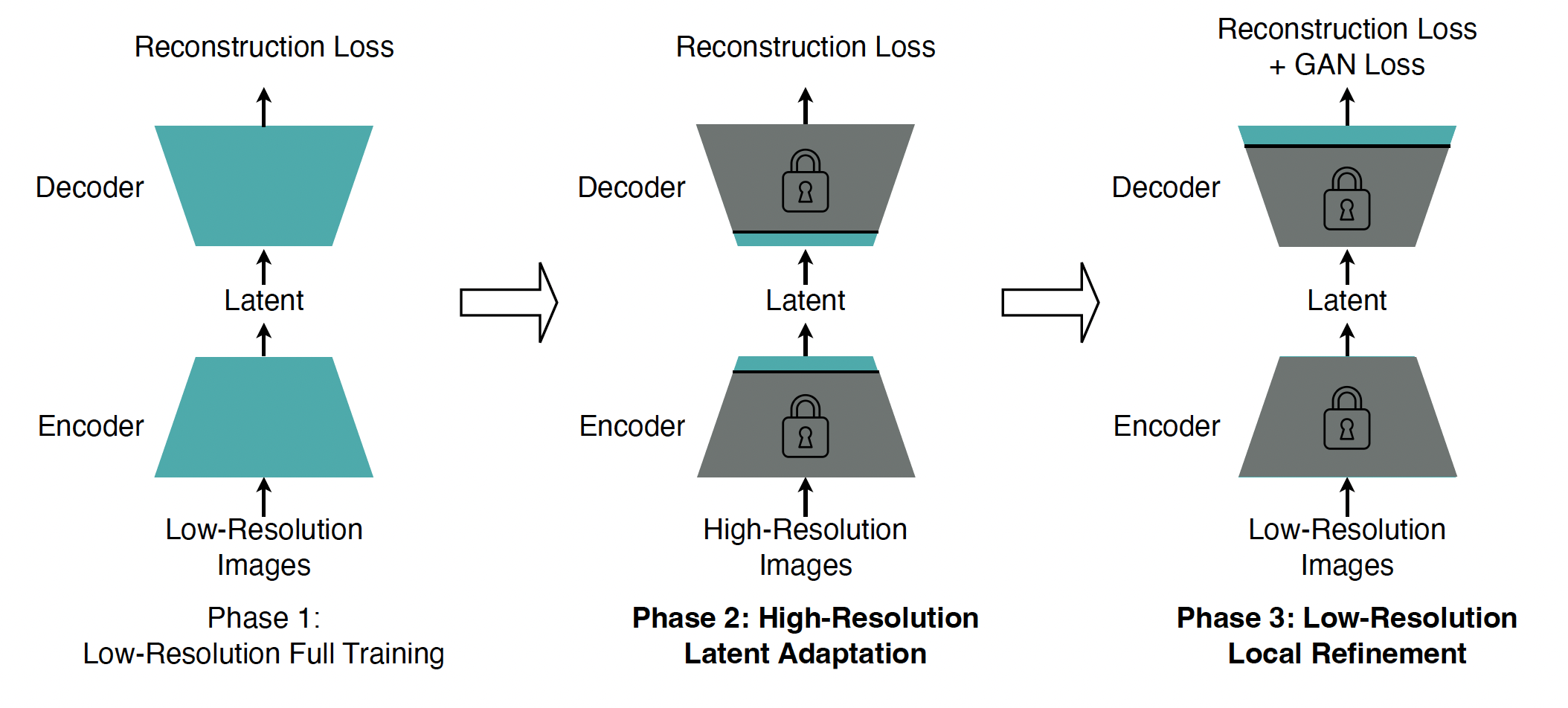
由于 reconstruction loss 单项就足以使得模型具有还原大致内容、语义的能力,因此可以仅在第三阶段才引入 GAN loss,并且只对模型的头部进行训练,冻结其余层。这样不仅提高了训练速度,而且避免了 GAN loss 训练对 latent space 的改变,避免了 unstable high-resolution GAN loss training。第二阶段只对中间层进行训练,但原因纯玄学,原文中也只有实验结果作为佐证。
SD-VAE 训练过程,reconstruction loss 与 GAN loss
Result
对于提高压缩率,一个简单的想法是沿用低压缩率的 autoencoder,并加上一个 space-to-channel 操作。那么 DC-AE 相较于该做法,效果如何?
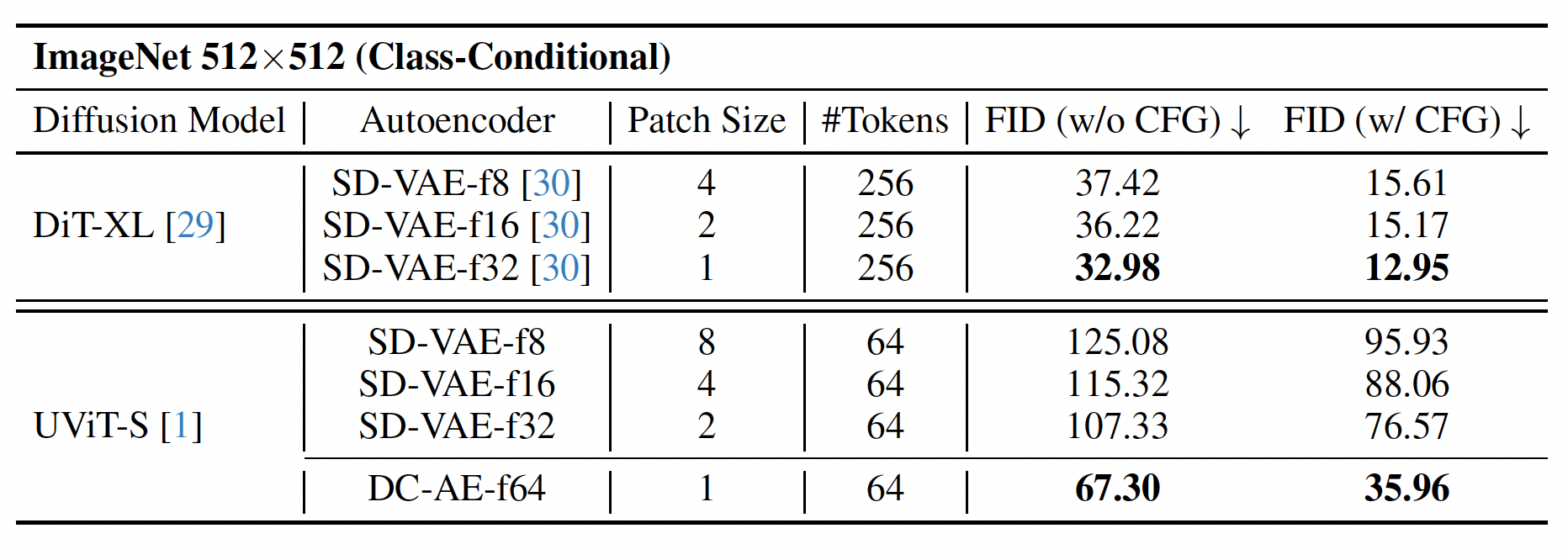
最直接的:DC-AE 效果很好。同时,文章还指出,当压缩任务从 diffusion model 转移到 autoencoder 时(即 autoencoder 压缩率提高、patch size 降低),训练效果也会提高。文章提出这是因为 diffusion model 能够专注于学习 denoise 过程。
- tokens、patch size 是啥?(LDM 里似乎没有讲)
- diffution model 的 token compression 是什么?
接下来是应用于 diffusion model 中的性能比较:
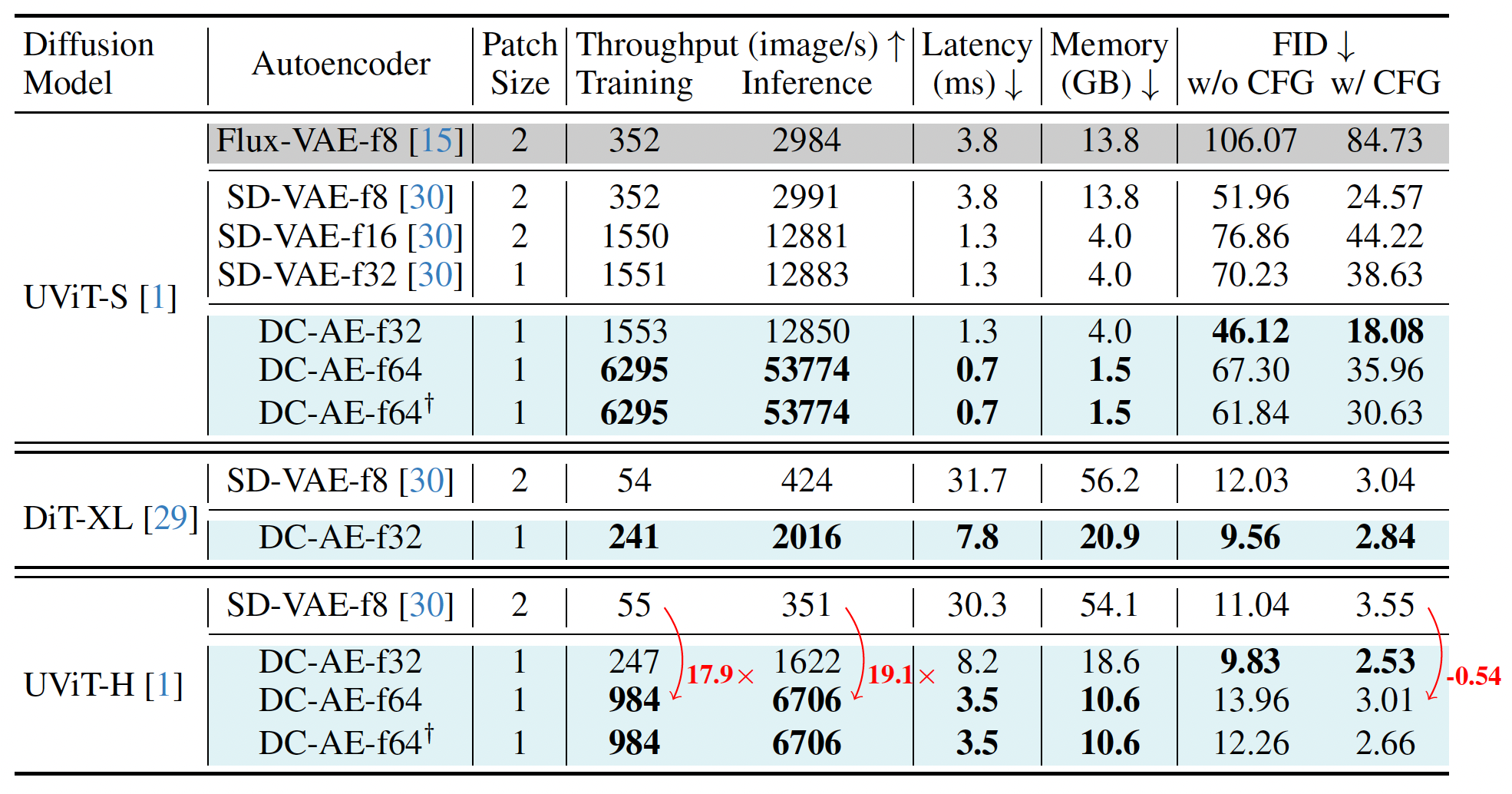
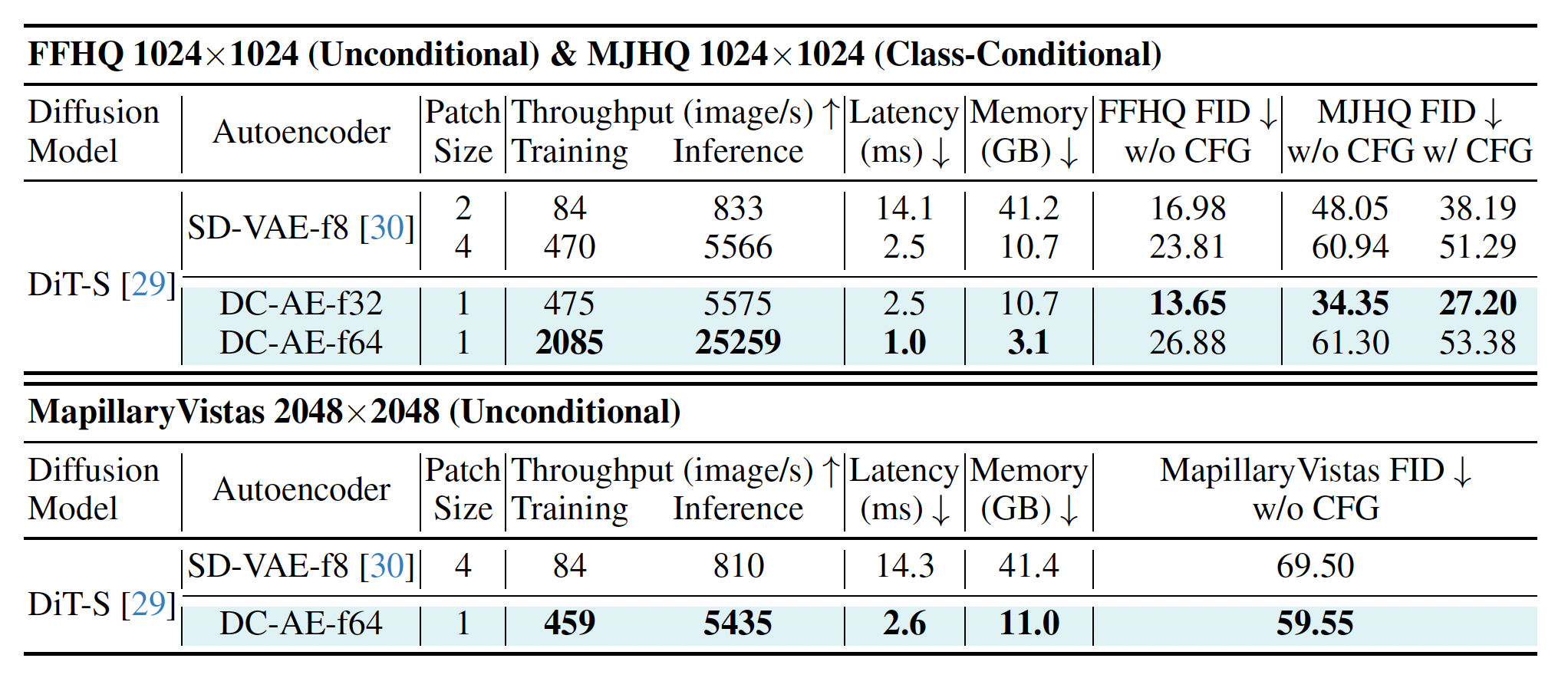

推理速度和内存占用都有显著提升。