Ctrl-World
Ctrl-World
发布于 ICLR 2026。
Overview
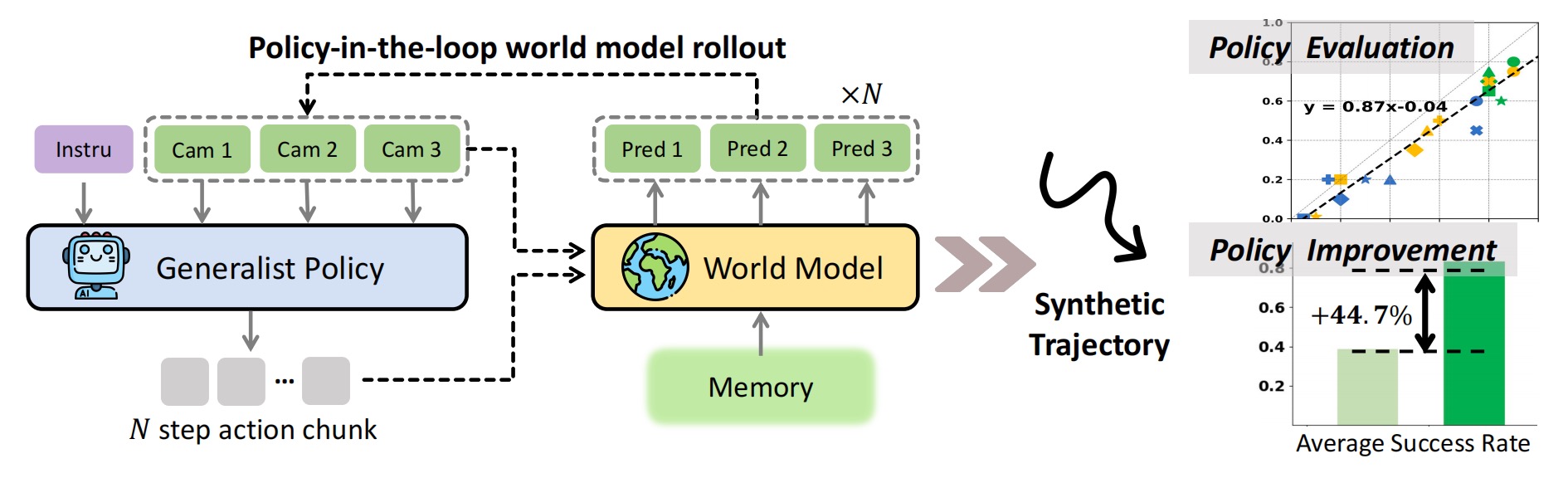
这篇文章想解决的问题不是直接训练一个更强的 VLA,而是给 VLA 提供一个可以交互的 world model:给定当前多视角观测、语言指令以及 policy 输出的 action chunk,world model 负责预测后续多视角视频。这样一来,policy 就可以在 imagination space 中 rollout,进而用于两件事:
- 在不真实执行机器人的情况下,评估不同 policy 的 instruction-following 能力;
- 在 world model 里搜索成功轨迹,并把这些 synthetic trajectories 拿来 fine-tune policy。
直观上,这和传统 model-based RL 的想法类似:如果有一个足够可靠的 dynamics model,就可以在模型里试错。但这里的 dynamics 不是低维状态转移,而是面向 generalist VLA 的多视角视频生成;action 也不是一次一步,而是现代 VLA 常用的 action chunk。
这篇文章最有意思的点在于,它并不试图把 world model 做成完全真实的物理模拟器,而是先抓住一个更弱但更实用的目标:让模型足够好地评估和改进 policy 的 instruction-following。
Problem
现代 VLA policy 已经能执行很多 manipulation 任务,但评估和改进仍然很重:
- 评估很贵:要在真实机器人上跑大量 rollouts,换物体、换指令、换场景都需要时间;
- 改进很贵:发现 failure case 之后,通常还需要重新收集专家数据;
- 已有 world model 不够对口:很多视频预测模型只做单视角、弱 action control,或者只适合 passive video prediction,无法和需要多视角输入的 VLA policy 闭环交互。
因此,Ctrl-World 的目标可以写成:
其中
Method
Ctrl-World 初始化自 1.5B 的 Stable Video Diffusion,并在此基础上加了三个改动。
Multi-View Joint Prediction
VLA policy 通常依赖多个 third-person cameras 和 wrist camera。单视角预测的问题是 partial observability 太严重,尤其在 contact-rich interaction 中,物体状态可能被遮挡,模型就容易出现类似“物体突然粘到 gripper 上”的 hallucination。
Ctrl-World 将
这样做有两个作用:一是匹配 VLA policy 的输入格式,二是让 wrist view 和 third-person view 相互补充。尤其是 wrist view,可以提供接触细节;third-person view 则提供全局空间关系。
Pose-conditioned Memory Retrieval
长时序生成的典型问题是误差累积。Ctrl-World 不是把所有历史帧都塞进去,而是以 stride
同时,将这些历史帧对应的 robot poses 通过 frame-wise cross-attention 注入到 spatial transformer 中。直觉上,相似 pose 往往对应相似的可见区域和交互状态,因此模型可以通过 pose 找回相关历史信息。
这里的 memory 更像是显式提供可检索的视觉锚点,而不是让 transformer 自己从很长上下文里硬记。
Frame-level Action Conditioning
预训练 SVD 只按文本和图像条件生成视频,并不知道机器人 action。Ctrl-World 将未来 action sequence 转换成 Cartesian-space robot arm poses,并和历史 poses 拼接:
随后,每一帧的 visual tokens 都通过 frame-wise cross-attention 访问自己对应的 pose embedding。这样做的目的,是让每一帧的视觉变化都和当前 action 对齐,而不是只在整段视频层面给一个粗粒度 action 条件。
训练目标仍然是 diffusion loss。记未来预测目标为
其中
Experiments
训练数据来自 DROID:约 95k trajectories、564 scenes,其中包含成功和失败轨迹。模型同时预测三个相机视角,每个视角分辨率为
World Model Quality
和 WPE、IRASim 等 action-conditioned world model 相比,Ctrl-World 在 10 秒 rollout 的视频预测指标上更好。Table 1 中,Ctrl-World 的 third-view 指标为:
- PSNR:23.56;
- SSIM:0.828;
- LPIPS:0.091;
- FVD:97.4。
消融实验也比较符合直觉:
- 去掉 memory,长时序一致性下降;
- 去掉 frame-level action conditioning,控制精度明显下降;
- 去掉 joint prediction,wrist-view 预测尤其变差。
Policy Evaluation
作者在新的 DROID setup 中测试
结论是:world model 对高层 instruction-following 的排序较可靠,但对低层物理执行成功率有低估倾向。作者也承认,碰撞、滑动、旋转、失败后重试等复杂动态仍然不够准。
Policy Improvement
改进 policy 的流程是:
- 从下游任务指令出发,在 world model 中 rollout;
- 通过 instruction rephrase 或随机初始 arm state 增加轨迹多样性;
- 每个任务生成 400 条轨迹;
- 用 human preference 保留 25-50 条成功轨迹;
- 用这些 synthetic trajectories 对
最终平均成功率从 38.7% 提升到 83.4%,也就是文章中强调的 44.7% 绝对提升。
Takeaways
核心贡献:Ctrl-World 不是提出一个全新的 video diffusion backbone,而是把 SVD 改造成 VLA-compatible world model。关键工程点是 multi-view joint prediction、pose-conditioned memory 和 frame-level action conditioning。
最重要的 insight:对于机器人 world model,可控性可能比单纯的视频真实感更重要。只要模型能稳定地区分不同 action 导致的未来差异,就可以服务于 policy evaluation 和 data generation。
可能的替代解释:效果不一定完全来自模型结构,也可能强依赖 DROID 的数据覆盖。文章自己也提到,DROID 中 dense action coverage 和 failure trajectories 对 controllability 很关键。
主要限制:
- world model 仍然不能精确处理复杂接触物理;
- policy improvement 依赖 human preference 筛选成功 synthetic trajectories;
- 目前主要验证的是 instruction-following,而不是低层执行能力的全面提升;
- 对 initial observation 比较敏感,说明 rollout 还没有真正摆脱分布问题。
这篇适合后续和 Mem-World 对比读。Ctrl-World 的 memory 仍然是 pose-conditioned sparse history;如果场景中存在严重遮挡、wrist camera 快速运动、物体状态只在早期可见,那么记忆检索本身可能成为瓶颈。
Problems
- 这里的 world model 到底需要多准?如果目标只是 ranking policy instruction-following,那么视觉 fidelity、物理 fidelity、action controllability 三者的最低要求分别是什么?
- 用 human preference 挑选成功 synthetic trajectories,本质上还是引入了人工标注。能否用 VLM reward model 替代?如果替代,reward hacking 会不会比真实机器人环境更严重?
- Ctrl-World 用 SVD 初始化,但机器人轨迹和自然视频的 motion prior 差异很大。预训练视频模型到底提供了什么:视觉先验、时序平滑先验,还是仅仅提供了一个大 diffusion backbone?
- 如果 world model 会低估 low-level success,那么用它筛出来的 synthetic successful trajectories 是否会偏向“视觉上看起来合理但物理上不可靠”的轨迹?
- 和传统 simulator 相比,这类 generative world model 的优势是数据驱动和视觉真实;劣势是不可验证、不可控误差。它更适合作为 evaluation proxy,还是作为 policy training data engine?